
Chapter 6 - Working with Data in Dash
Contents
Chapter 6 - Working with Data in Dash¶
What you will learn¶
In this chapter we will show you how to incorporate data into Dash apps. There are many ways one could add data to an app, but we will focus on a few of the most common ways when working with Dash.
Learning Intentions
read data into the app
create and populate Pandas dataframes
basic data wrangling techniques to prepare data for reporting
By the end of this chapter you will know how to build this app:
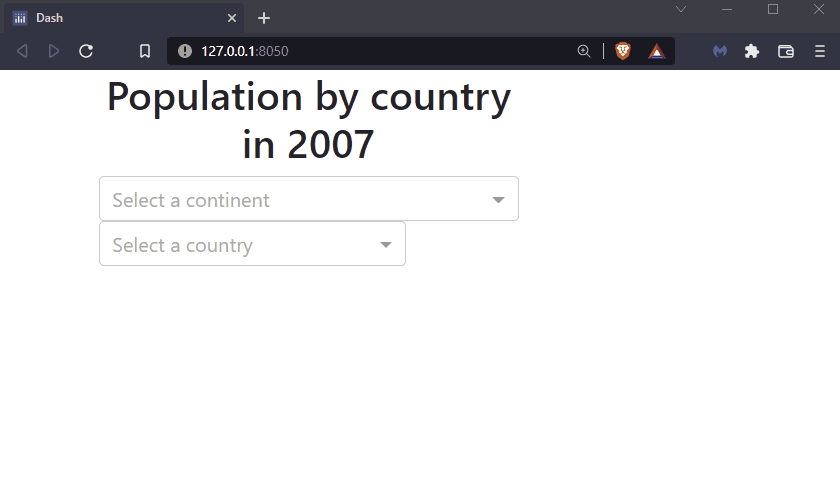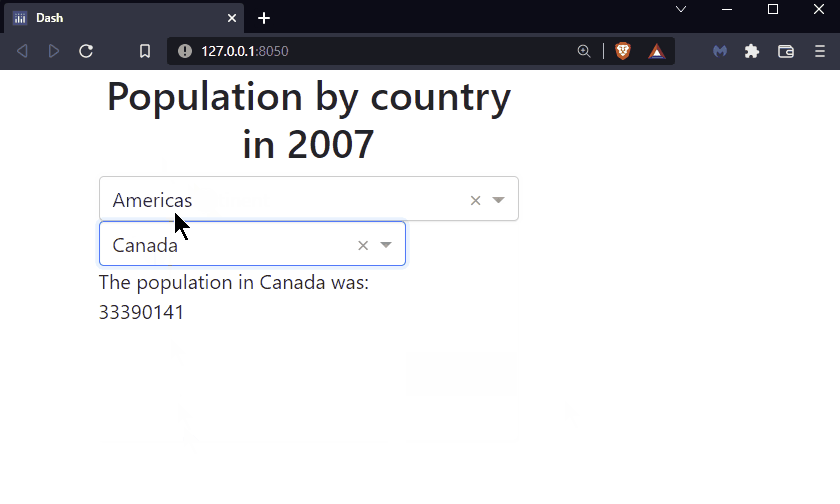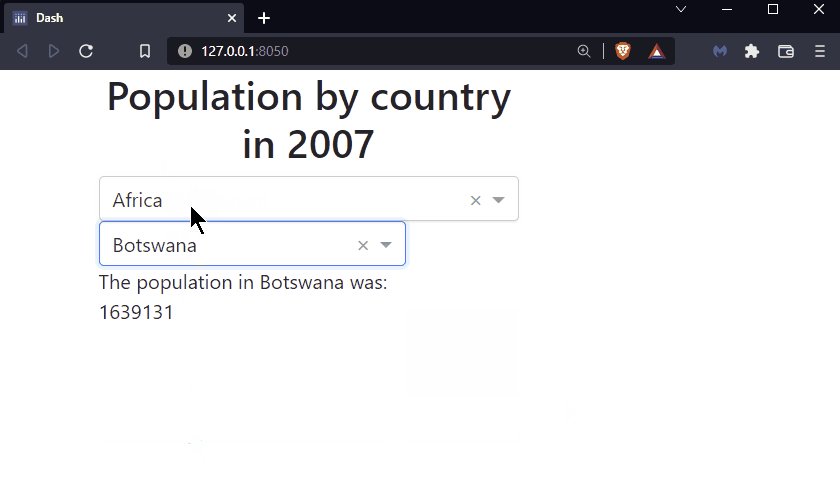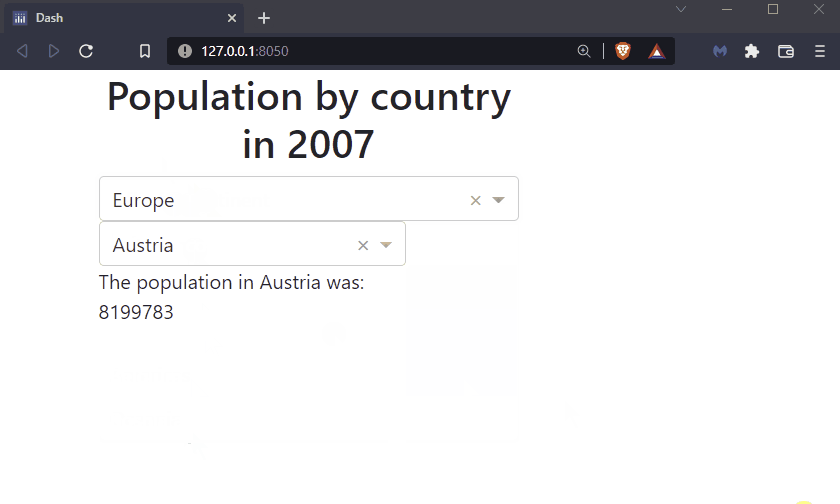
See the code
# Import packages
from dash import Dash, dcc, Input, Output, html
import dash_bootstrap_components as dbc
import pandas as pd
# Import data
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df3 = pd.read_csv(url, sep=';')
y=2007
df3 = df3.loc[(df3['year']==y), :]
# Initialise the App
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
# Create app components
_header = html.H1(children = 'Population by country in 2007', style = {'textAlign' : 'center'})
continent_dropdown = dcc.Dropdown(id = 'continent-dropdown', placeholder = 'Select a continent', options = [c for c in df3.continent.unique()])
country_dropdown = dcc.Dropdown(id = 'country-dropdown', placeholder = 'Select a country')
_output = html.Div(id = 'final-output')
# App Layout
app.layout = dbc.Container(
[
dbc.Row([dbc.Col([_header], width=8)]),
dbc.Row([dbc.Col([continent_dropdown], width=8)]),
dbc.Row([dbc.Col([country_dropdown], width=6)]),
dbc.Row([dbc.Col([_output], width=6)])
]
)
# Configure callbacks
@app.callback(
Output(component_id='country-dropdown', component_property='options'),
Input(component_id='continent-dropdown', component_property='value')
)
def country_list(continent_selection):
country_options = [c for c in df3.loc[df3['continent']==continent_selection, 'country'].unique()]
return country_options
@app.callback(
Output(component_id='final-output', component_property='children'),
Input(component_id='country-dropdown', component_property='value'),
prevent_initial_call=True
)
def pop_calculator(country_selection):
pop_value = df3.loc[df3['country']==country_selection]
pop_value = pop_value.loc[:, 'pop'].values[0] # select only first value in pop column
output = ('The population in '+country_selection+' was: '+pop_value.astype(str))
return output
# Run the App
if __name__ == '__main__':
app.run_server()
6.1 Where to read in the data¶
The data which is imported into Dash apps will be used by multiple objects: Dash components, callbacks, tables, layout, etc. For this reason, we recommend importing the data before initialising the app, right above this line of code:
# Data imported here
# Initialise app
app = Dash(__name__)
In this way, the data will be globally available to all objects that are created in the code.
One of the most common cases for incorporating data into our app is when we need to quickly test out a piece of code. In those cases, we can build our own data set through a pandas dataframe. An empty dataframe is created with the code below:
# Data imported here
test_data = pd.DataFrame()
# Initialise app
app = Dash(__name__)
Then, some mock-up data can be added using a dictionary:
test_data = pd.DataFrame({'Country':['United States','Norway','Italy','Sweden','France'],
'Country Code':['US','NO','IT','SE','FR']})
The dictionary keys Country and Country code will represent the column names of the pandas dataframe.
Note
If you need access to pre-built data sets to test your code, consider using the Plotly Express built-in data, such as Gapminder or other data, which can be added to your app with these commands:
df = px.data.gapminder()
6.2 Uploading data into an app¶
Whether our data is located on our computer or on the internet, we can read the data from the source and convert it into a pandas dataframe. There are several ways of uploading data into our app; we will focus on these methodologies, as they are commonly used by Dash app creators:
reading data from files on our computer (.xls, .csv, .json)
reading data from the web (via URL)
6.2.1 Reading data from files on your computer¶
Excel files¶
Let’s see an example of how to upload an Excel file - extracted from the Gapminder data - into a pandas dataframe.
The file we’ll be using is available here data_01: follow the link and click “Download”; find the folder in your computer where the file was downloaded and copy the path. For example, on our computer the path was C:/Users/Desktop/Downloads.
Create a new app.py file, copy the code below into that file, and run it.
Note
Note that you will need to pip install openpyxl into your terminal in order to work with .xlsx files.
import pandas as pd
filepath = r'C:/Users/Desktop/Downloads/data_01.xlsx'
df1 = pd.read_excel(filepath, sheet_name='Sheet1')
print(df1)
You should see this output in the terminal if the app.py file executed successfully.
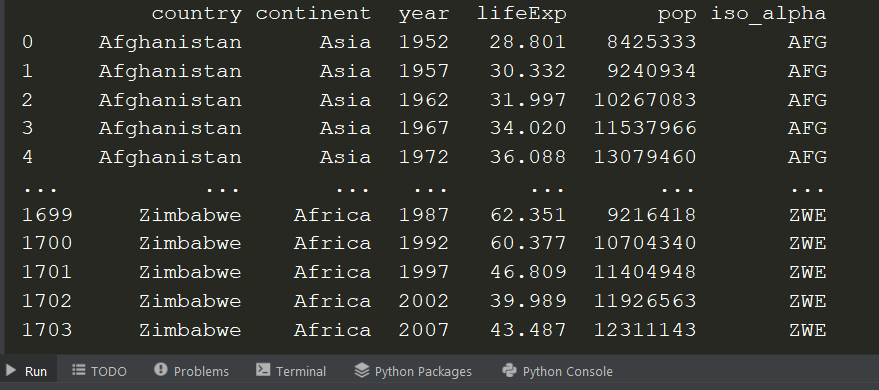
In this example, we have accessed the data (Excel file) from outside the folder where we placed the app.py file; therefore, we specified a filepath. The path is saved as a raw string (hence the “r” just before the string containing the path. This is done because VS Code may trigger a warning when using a normal string).
If the data file is inside the folder where your app.py file is located (or within the VS Code working directory), the full path is not necessary; you may only specify the filename. The code will then become:
import pandas as pd
filepath = 'data_01.xlsx'
df1 = pd.read_excel(filepath, sheet_name='Sheet1')
print(df1)
Note
If you experience any difficulties in finding your filepath, please check this screenshot, showing how to find the filepath directly from VS Code.
{kind=link}
Tip
In production versions, when apps get deployed, the best practice is to have a “data” folder, where all data files are stored and therefore accessed by the app code.
CSV files¶
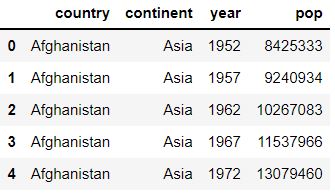
We will now upload the same data from above, but from a .csv file named data_02. Please follow the link and click the “Raw” button (next to the pencil edit button), then paste the records into a new Notepad file (Windows) or TextEdit file (MacOS), and save it as “data_02.csv”. Create a new app.py file and copy the code below into it. Update the filepath in the code with the path of your Notepad file.
import pandas as pd
filepath = r'C:/Users/User1/Downloads/data_02.csv'
col_names = ['country','continent','year','pop']
df2 = pd.read_csv(filepath, sep='|', usecols=col_names)
print(df2.head())
In most cases, you will see .csv files with comma column separators (hence the name, csv standing for “comma-separated values”). Here, we used a different separator: ‘|’. The
separgument allows to specify whatever characters should be considered field separators: pandas will separate data into different columns any time it encounters these characters.We have also selected a subset of columns to be uploaded, listed in the
usecolsargument. The remaining columns that are present in the file will be ignored.
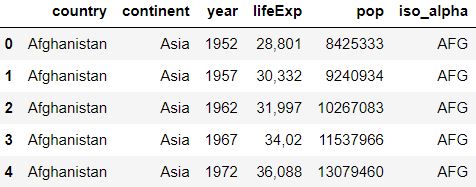
6.2.2 Reading data from the web (URL)¶
We will now upload the same data from above, but from this ULR.
import pandas as pd
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df3 = pd.read_table(url, sep=';')
print(df3.head())
Note
The above URL is a link to a .txt file that is online. The pd.read_table() function will work for other file formats too, such as .csv files.
The code above, will generate a dataframe that looks like:
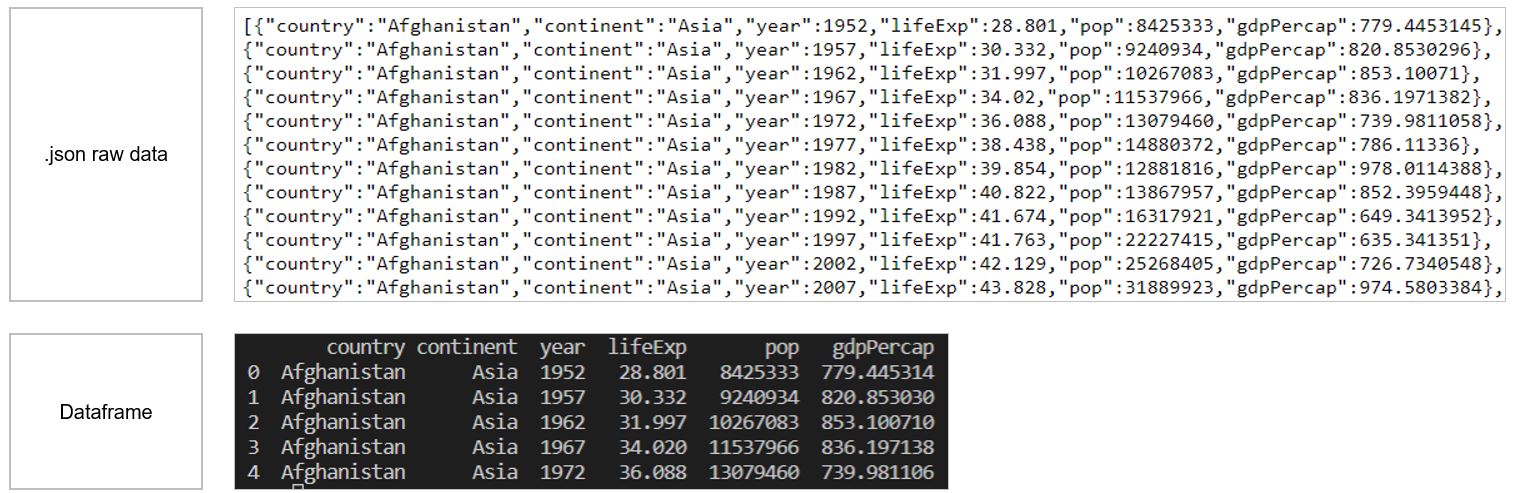
Reading data from a json file¶
We will now upload data stored in json format. You may encounter this file format when working with API or web services as it is mostly used to interchange data among applications. In our case, the json data we’ll upload is available on this URL.
Pandas includes a specific function to process json files: pd.read_json()
import pandas as pd
url = 'https://cdn.jsdelivr.net/gh/timruffles/gapminder-data-json@74aee1c2878e92608a6219c27986e7cd96154482/gapminder.min.json'
df4 = pd.read_json(url)
print(df4.head())
6.3 Data wrangling basics¶
Once we have our dataframe available, some transformations may be needed in order to use the data in our app. There is a vast list of methods and functions that can be applied to Pandas dataframes (you may refer to this documentation for more info). In this section we’ll cover a few wrangling techniques that are most commonly used when building Dash apps.
The below examples are based on the “df3” dataframe that we created above by reading data from a URL.
Unique values¶
When exploring data, we may often need to identify the unique values in each column:
df3.continent.unique()
With the above command, an array containing the unique values in the column will be displayed.
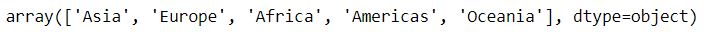
Slicing¶
The .loc method can be used in Pandas dataframes to slice or filter the data based on boolean conditions (True, False).
The .loc[(), ()] method will filter based on row conditions (to be specified in the first bracket ()) and on column conditions (to be specified in the second bracket ()).
Let’s see two examples:
df3_Slice1 = df3.loc[(df3['continent']=='Americas'), :]
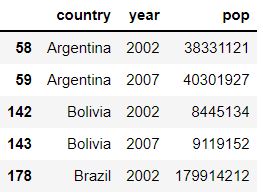
df3_Slice2 = df3.loc[(df3['continent']=='Americas') & (df3['year'].isin([2002,2007])), ['country','year','pop']]
print(df3_Slice2.head())
The first command will filter the df3 dataframe picking rows that have ‘Americas’ as continent. The : indicates that we don’t want to specify any column-filtering conditions, hence, all columns will be selected.
The second command adds more row-filtering conditions: rows will be filtered based on American continent and also on ‘year’, which must be either 2002 or 2007. Additionally, only three columns will be saved into df3_Slice2, namely: country, year, pop. The second command results in:
As an alternative to the .loc method, this is another powerful way to access rows that match a certain condition. The first slicing criteria above can also be obtained via:
df3[df3['continent']=='Americas']
Grouping¶
The .groupby method can be used on Pandas dataframes to aggregate data: data will be split according to the unique values in the grouped fields, allowing to perform computations on each group.
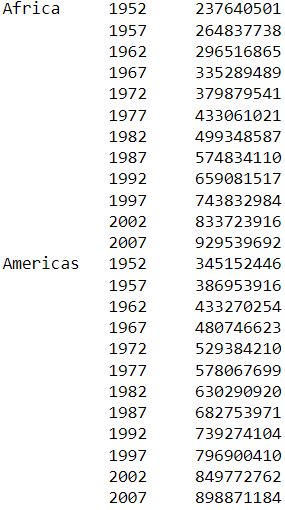
As an example, let’s calculate the yearly population by continent, summing up the populations from all countries within each continent:
df3.groupby(['continent','year'])['pop'].sum()
The result will look like:
6.4 Using data in the App¶
Let’s now see how to use the data we’ve uploaded through a couple of examples.
Example 1¶
In the below app, we import the “df3” dataframe that we created above, and use the list of unique continents to create the “options” of a Dropdown component. Using the callback, an output message is shown based on the selected dropdown value.
# Import packages
from dash import Dash, dcc, Input, Output, html
import dash_bootstrap_components as dbc
import pandas as pd
# Import data
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df3 = pd.read_table(url, sep=';')
# Initialise the App
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
# Create app components
continent_dropdown = dcc.Dropdown(id='continent-dropdown', options=df3.continent.unique())
continent_output = html.Div(id='continent-output')
# App Layout
app.layout = dbc.Container(
[
dbc.Row([dbc.Col([continent_dropdown], width=8)]),
dbc.Row([dbc.Col([continent_output], width=8)])
]
)
# Configure callback
@app.callback(
Output(component_id='continent-output', component_property='children'),
Input(component_id='continent-dropdown', component_property='value')
)
def dropdown_sel(value_dropdown):
if value_dropdown:
selection = ("You've selected: "+value_dropdown)
return selection
else: ""
# Run the App
if __name__ == '__main__':
app.run_server()
The above code will generate the following App:

Example 2¶
We will now build upon the previous example, including a second dropdown, linked to the first one. The second dropdown will show the list of countries from the continent selected in the first dropdown. Based on the selected country, the total population will be displayed.
Note
This is often referred to as the chained callback. See Dash documentation for more examples.
# Import packages
from dash import Dash, dcc, Input, Output, html
import dash_bootstrap_components as dbc
import pandas as pd
# Import data
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df3 = pd.read_csv(url, sep=';')
y=2007
df3 = df3.loc[(df3['year']==y), :]
# Initialise the app
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
# Create app components
_header = html.H1(children='Population by country in 2007', style={'textAlign': 'center'})
continent_dropdown = dcc.Dropdown(id='continent-dropdown', placeholder='Select a continent', options=df3.continent.unique())
country_dropdown = dcc.Dropdown(id='country-dropdown', placeholder='Select a country')
_output = html.Div(id='final-output')
# app Layout
app.layout = dbc.Container(
[
dbc.Row([dbc.Col([_header], width=8)]),
dbc.Row([dbc.Col([continent_dropdown], width=8)]),
dbc.Row([dbc.Col([country_dropdown], width=6)]),
dbc.Row([dbc.Col([_output], width=6)])
]
)
# Configure callbacks
@app.callback(
Output(component_id='country-dropdown', component_property='options'),
Input(component_id='continent-dropdown', component_property='value')
)
def country_list(continent_selection):
country_options = df3.loc[df3['continent']==continent_selection, 'country'].unique()
return country_options
@app.callback(
Output(component_id='final-output', component_property='children'),
Input(component_id='country-dropdown', component_property='value'),
prevent_initial_call=True
)
def pop_calculator(country_selection):
pop_value = df3.loc[df3['country']==country_selection]
pop_value = pop_value.loc[:, 'pop'].values[0] # select only first value in pop column
output = 'The population in '+country_selection+' was: '+pop_value.astype(str)
return output
# Run the app
if __name__ == '__main__':
app.run_server()
Tip
In the code above, you may notice that in the second callback we have added this line: prevent_initial_call=True. This is necessary because the second callback depends on the first callback, which does not get triggered until the user selects a dropdown value. By default, Dash triggers every callback when initialising the app. We want to prevent the initial activation of the second callback, as Dash wouldn’t find any input value for this callback until the first callback is executed.
The above code will generate the following app:
Exericses¶
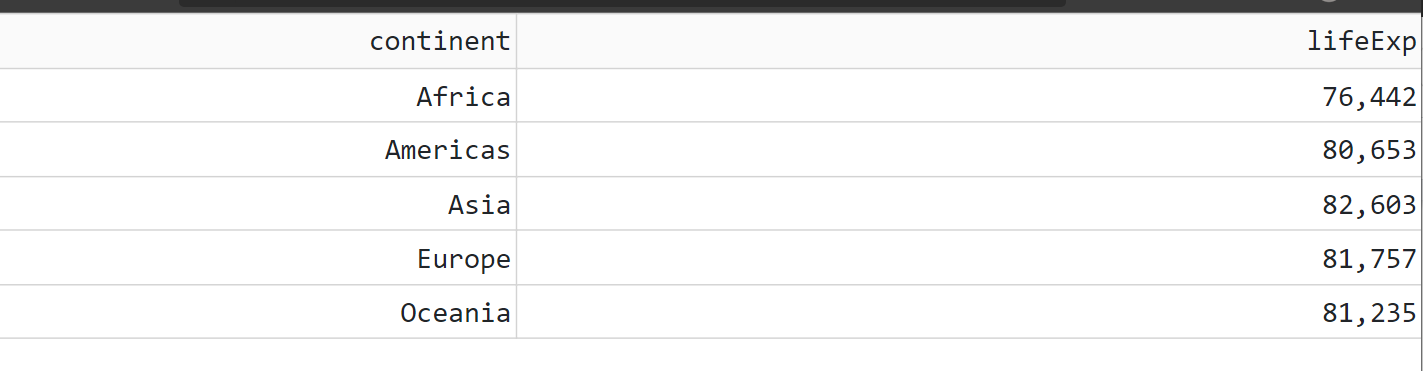
(1) Build the following steps in Python (this data will be used in the next exercise app):
Import the gapminder data from this ULR
Filter data by year greater or equal than 1980
Group the data by continent and calculate the max life expectancy
See Solution
from dash import Dash, html, dcc, dash_table
import dash_bootstrap_components as dbc
import pandas as pd
# Import data
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df_ = pd.read_csv(url, sep=';')
df_ = df_.loc[df_['year'] >= 1980, :]
df_ = df_.groupby('continent')['lifeExp'].max().reset_index()
print(df_.head())
# Initialise the app
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = html.Div([
dash_table.DataTable(df_.to_dict('records'))
])
# Run the app
if __name__ == '__main__':
app.run_server()
(2) Build a Dash app that imports and wrangles the data as per exercise 1; then, display the max life expectancy as the children of a Markdown component, based on a continent that the user can choose from a RadioItems component.
See Solution
# Import packages
from dash import Dash, dcc, Input, Output, html
import dash_bootstrap_components as dbc
import pandas as pd
# Import data
url = 'https://raw.githubusercontent.com/open-resources/dash_curriculum/main/tutorial/part2/ch6_files/data_03.txt'
df_ = pd.read_csv(url, sep=';')
df_ = df_.loc[df_['year'] >= 1980, :]
df_ = df_.groupby('continent')['lifeExp'].max().reset_index()
# Initialise the app
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
# Create app components
_header=html.H1(children='Life Expectation by continent since 1980', style={'textAlign': 'center'})
continent_radio=dcc.RadioItems(id='continent-radio', options=df_.continent.unique(), value='Africa')
output_=dcc.Markdown(id='final-output')
# app Layout
app.layout = dbc.Container(
[
dbc.Row([dbc.Col([_header], width=8)]),
dbc.Row([dbc.Col([continent_radio], width=8)]),
dbc.Row([dbc.Col([output_], width=6)])
]
)
# Configure callbacks
@app.callback(
Output(component_id='final-output', component_property='children'),
Input(component_id='continent-radio', component_property='value')
)
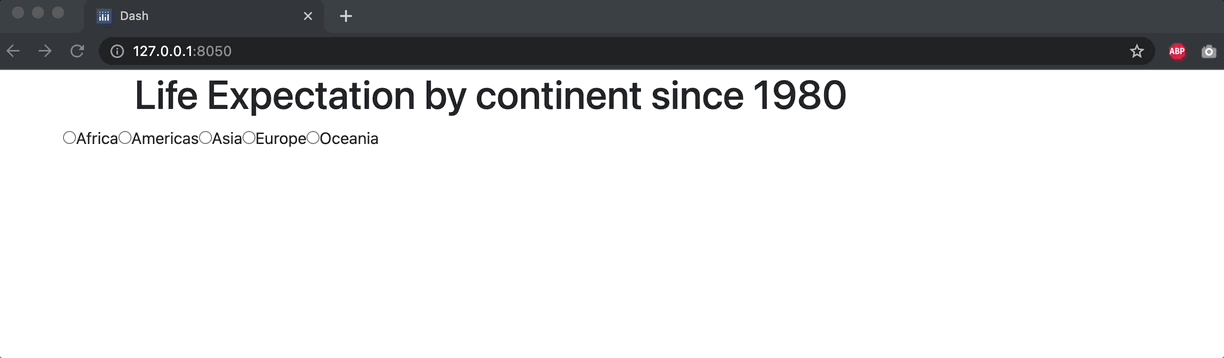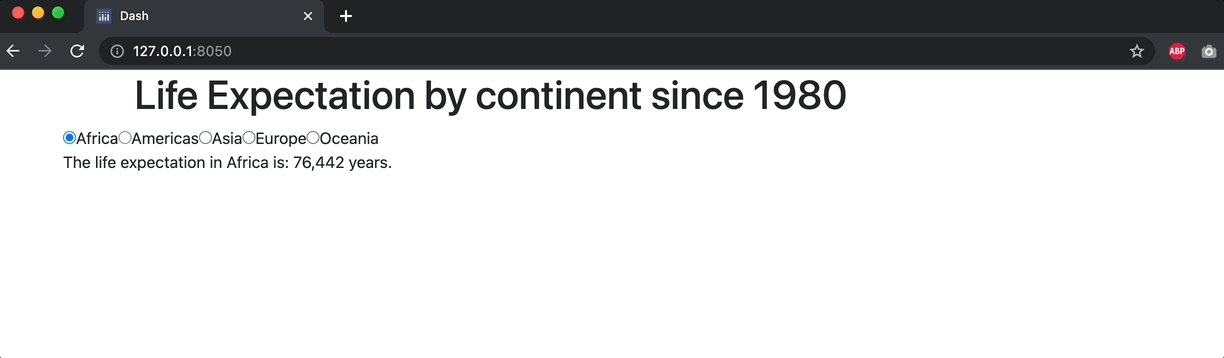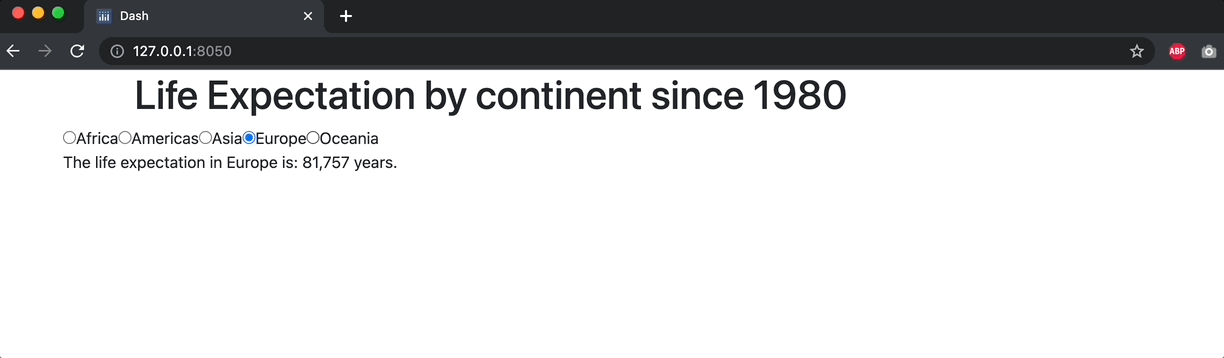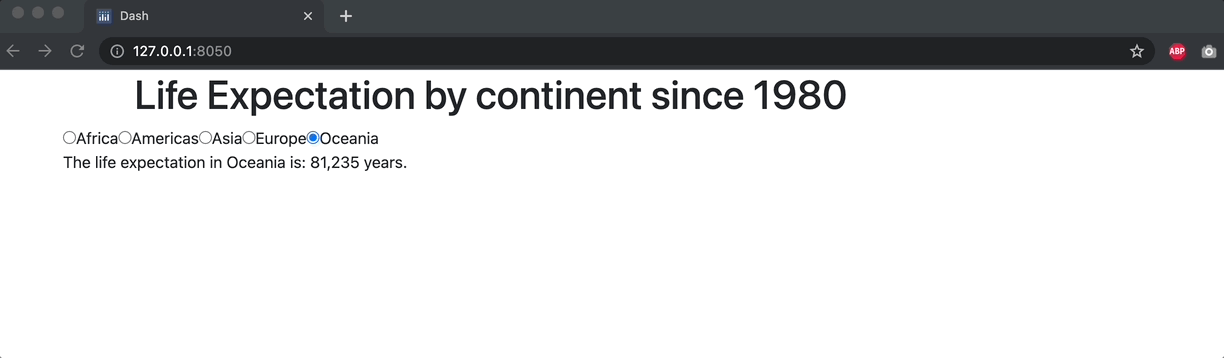
def continent_lifeExp(continent_selection):
lifeExp_value = df_.loc[df_['continent']==continent_selection, 'lifeExp'].values[0]
output = ('The life expectation in '+continent_selection+' is: '+lifeExp_value+' years.')
return output
# Run the app
if __name__ == '__main__':
app.run_server()
Summary¶
In this chapter, we have explored several options to upload data into a pandas dataframe that will be used inside a Dash app. We went through some basic data wrangling techniques that prepare our data for usage by the Dash components.
In the next chapter we will dive deeper into data wrangling.